By Claudio Bozzato and Lilith [^.^];.
As part of our continued research into Microsoft Azure Sphere, there are two vulnerabilities we discovered that we feel are particularly dangerous. For a full rundown of the 31 vulnerabilities we’ve discovered over the past year, check out our full recap here.
This blog post documents the entirety of our second Azure Sphere local privilege escalation bug chain (see our first one here). This LPE is a full Azure Sphere kernel exploit that was written without access to a kernel debugger. This work was presented at Hitcon 2021.
Linux Kernel /proc/pid/syscall information disclosure vulnerability (TALOS-2020-1211)
Microsoft Azure Sphere Kernel pwm_ioctl_apply_state kfree() code execution vulnerability (TALOS-2021-1262)
The pwm_ioctl_apply_state bug, fixed in version 21.03, allowed us to call kfree() on any address of our choosing, a rather powerful primitive. As such, we opted to try and free the azure_sphere_task_cred heap object that was connected to our current userland process. This cred structure controls the Azure Sphere specific capabilities we have, which is the permission needed to talk to /dev/pluton and /dev/security-monitor, a requirement for further escalation.
Initially, the thought was, "When in doubt, try everything." If we kfree() every kernel heap chunk, there had to be an address that'd work, right? Since the azure_sphere_task_cred was 0x58 bytes in size and allocated in the kmalloc-128 kmem_cache, we could reduce our search space by iterating over every 0x80 bytes.
To see if our kfree() had successfully freed our azure_sphere_task_cred or not was actually quite trivial and could be done in a variety of ways. The simplest, however, was just doing a kernel heap spray on size 0x80 slabs after kfree()'ing and then checking /proc/self/attr/current, which would dump most of our azure_sphere_task_cred:

As long as CAPS: 00000000 was showing up, we'd know that nothing significant had happened due to our kfree(), and likewise, if the device crashed, we'd know that something too significant happened.
The implementation of this brute force was rather simple, but difficulty again struck however as the Azure Sphere device became slightly unruly when freeing particular kernel addresses (who could have guessed?) and would subsequently not respond to USB commands to reboot. Thus we had to spin up a more forceful reset mechanism via a network-connected power outlet:

Following this slight detour, we successfully iterated over kfree addresses, and eventually (usually overnight) reached a state where our process' azure_sphere_task_cred was successfully kfree'd and overwritten with a kernel heap spray of (almost) fully controlled Linux mqueue messages (since they had been optimized into the generic kmem caches).

But a problem still, unfortunately, remained in that a runtime of 8 - 10 hours, thousands of reboots, and a specific hardware setup is probably not the most optimal set of requirements for an exploit to have.
You just got to free the right address, easy, right?
Amazingly and unfortunately, heaps are usually non-deterministic beasts and the location of our azure_sphere_task_cred was not in a fixed address across reboots. Thankfully, we had a bug in our back pocket: the briefly aforementioned Linux kernel leak, which affects all 32-bit Linux ARM systems. In Azure Sphere, this had initially not been deemed worth a fix because there is no KASLR enabled on the device, however, it has later been fixed in 21.02 since (we assume) this exploitation chain proved that such a leak aids exploitation. On the other hand, Linux fixed this issue in version 5.10.
The leak itself was a pretty basic bug, the most trivial POC being cat /proc/self/syscall. On our Azure Sphere, such a request would look like so, the last five columns being leaked kernel memory:

Due to the stack-based nature of this vulnerability, the data we could leak was limited to a specific set of bytes at a specific offset from the kernel stack's base. While obviously not optimal, we played with what we had — a bit easier than finding another Linux kernel info leak.
Since we were testing via busybox's cat command initially, which uses the sendfile() syscall under the hood, we found the leak was at offsets $sp-0x3c8 to $sp-0x3b0 (via testing in a separate 32-bit ARM QEMU image). Since this was a rather high offset from our process' kernel stack base, we first tried finding candidate syscall code paths, accessible by a normal user, to spray useful data high enough into the kernel stack.
While we did find such a function in the littlefs code path when repeatedly creating and deleting the same file in /mnt/config/<uuid> (a unique file path assigned to each given application for non-volatile storage), this approach was not useful, as the data populated into the leaked stack slot was useless. More importantly, this code path slowed down our leaking thread enough that the number of unique leaks was rather negligible. We gathered more unique data from our information leak when we focused solely on leaking, leaving the population of data to the different kthreads and other processes' syscalls (instead of spraying the kernel stack ourselves).
The next development was the realization that the different Linux syscalls for reading a file would each cause a different stack offset to leak since there's enough difference in their initial code flows into the kernel. The syscalls and their corresponding leak offset are as such:

Each syscall had its own set of unique data, each with its own set of leaked pointers. We first attempted to free all the leaked pointers from all the different syscalls and gather as much unique data as possible. If a given leak had a kernel .text address (to use as a reference point) and also a kernel heap pointer that was 0x80 aligned, we'd try to free it.

Once again, failure graced our efforts, as all the leaked pointers either caused an immediate crash or did not change our current Azure Sphere capabilities — a new approach was needed.
Catching a break
Coming full circle, we decided to go with the tried and true approach, applicable in literally all situations, no exception: brute force. First, we would wait overnight until the kfree() brute-force bestowed upon us escalated privileges and then we'd leak memory via /proc/self/syscall.
This approach allowed us to gather information leak samples while also knowing what the actual azure_sphere_task_cred slab address was. This gave us more context to the usefulness of each leaked pointer and eventually, by once again trying all the unique leaks pointer addresses, we found a winner.

Since the kernel's .text address was shifted back to 0xbf800000 (instead of the common 0xc0000000), we'd search for 0xbf86f5ec, 0xbf86f065, 0xbf86f4f2, or 0xbf86f327 in the sixth column (which should hopefully be constant) and then try freeing all the 0x80 aligned addresses within the page of slab pointer in column four. With this approach, we achieved a great amount of exploit stability, around 97 percent.


Conversion to arbitrary kernel code execution
While having full Azure Sphere capabilities allowed us to utilize almost all of /dev/security-monitor's and /dev/pluton's ioctls, we still needed to examine potential attack surfaces that might not be accessible strictly from ioctl(). As such, we quickly decided to turn this current set of bugs into arbitrary kernel code execution.
Since the azure_sphere_task_cred was overwritten with a Linux mqueue msg_msg structure (again, both in generic kmem_cache), it behooves us to examine exactly why msg_msg structures are such a powerful exploitation primitive, and why they were probably moved to named kmem caches in the first place.

First, they're variable length (up to a compile-time config maximum), so we can place them in basically any generic kmem_cache (unless they're in a named kmem_cache, like they should be). Second, you can fully control the actual message contents.
Third, if you can manage to corrupt one's struct list_head m_list member and then free it (via mq_receive), you can get an attacker-controlled four-byte mirror-write to an arbitrary address when the msg_msg structure is removed from its linked list.
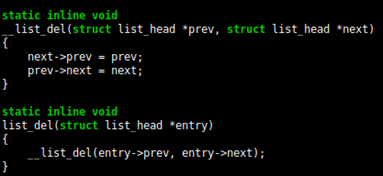
So, how do we re-corrupt our azure_sphere_task_cred/struct msg_msg slab? It turned out to be rather trivial since /proc/self/attr/exec allows you to write to the azure_sphere_task_cred from the azure_sphere_security_setprocattr function if the is_app_man bool is set. Normally this is_app_man boolean is never set, except when application_manager (Azure Sphere's init) spawns a process and gives it a subset of AZURE_SPHERE_CAPs. However, since we’re spraying the contents of azure_sphere_task_cred, we initially control the value of is_app_man, which we thus arbitrarily set to 1. This way, we can re-corrupt the same slab again to corrupt the struct msg_msg.

Thus, to set up an arbitrary mirror-write, we could literally just echo aaaaaaaaaaaaaaaaaa > /proc/self/attr/exec after kfree()'ing our kernel slab again to re-corrupt it. This second kfree() is needed since normal Linux credential structure maintenance code causes a new azure_sphere_task_cred to be allocated and we need to maintain the same slab address.
So what to write and where to write it? Keep in mind that since the write primitive is mirrored, both pointers need to be writable. A trivial way to tackle this would be to overwrite a function pointer in the kernel, that jumps to a shellcode stored in userland. We soon realized however that PXN was enabled after getting device reboots whenever we tried to call userland shellcode. We did also find, through manual testing, that PAN was not enabled, so we could read and write userland data from the kernel.
With this knowledge in hand, we exploited the LSM linked list and overwrote the LSM entry for prctl, since it allowed for full control over all the LSM hook function arguments. This way, we can call the prctl syscall from userland, triggering the LSM hook for prctl that we overwrote with an arbitrary function pointer (e.g. memcpy), which would be called with mostly arbitrary parameters (those specified in the prctl syscall). Since this lets us call arbitrary functions with arbitrary parameters, we effectively are running arbitrary code in the kernel, and we can even inject and execute shellcode stubs if needed.
Note that if PAN had been enabled, we still would have been able to exchange data with the kernel via the struct msg_msg spray.
 |
Example kernel function call. |
Post-Kernel Landscape
From this point on, we'll be exclusively referring to the ARM TrustZone implementation as "Secmon" and the M4 security core as "Pluton.” If we're talking about the kernel drivers, we’ll refer to them by path (/dev/security-monitor and /dev/pluton).
When the kernel normally communicates with Pluton or Secmon, it's usually through ioctls to these /dev kernel drivers, a subset of which don't actually communicate with their respective endpoints. But in most cases, these ioctls end up being populated into an azure_sphere_syscall structure.

This structure is processed, sanitized, and subsequently shipped off to Pluton via a Linux mailbox overlaid onto a DMA memory buffer shared between cores, or to Secmon via ARM's SMC instruction and passing a buffer again to this shared DMA memory buffer. The shared DMA memory area is in range 0x80000000-0x803d0000.
Upon being received by the respective endpoint, the code in Secmon and Pluton is basically the same until the individual syscalls get processed. Each endpoint has a set of structures that defines the available syscalls, the types of each of the arguments, the syscall itself, and the syscall-specific validation that must be passed beforehand. Example structures for Pluton and Secmon are below.

The full list of syscalls for both Secmon and Pluton is rather sizeable:

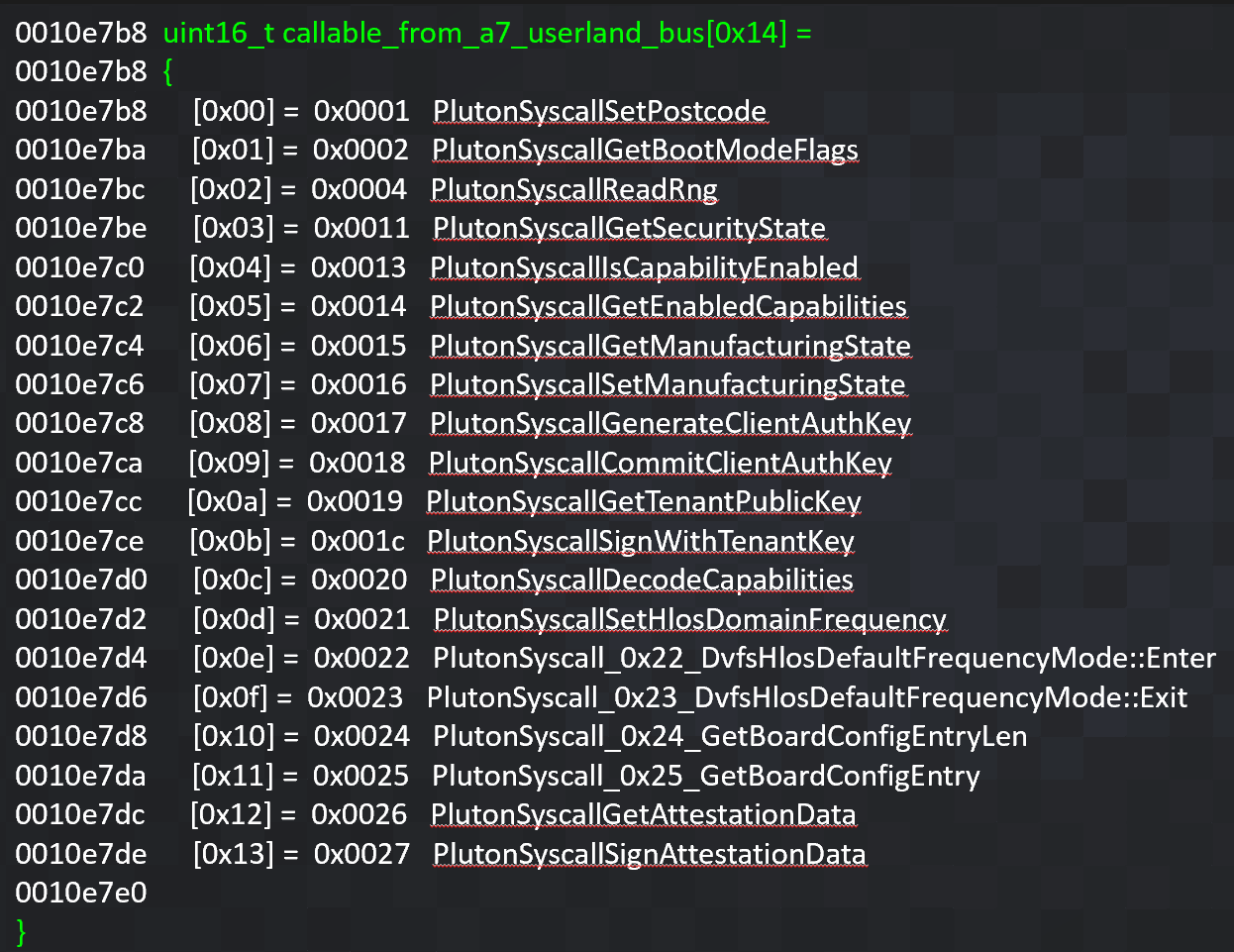
Worth noting about Pluton: Only a subset of the Pluton syscalls (listed above) are actually accessible from the Linux Normal World. The rest of the syscalls can only be hit by Secmon, which has its own private shared memory mailbox with Pluton.
Within Pluton/Secmon, each of these syscalls has a unique set of arguments, and all pointer arguments are validated to reside in the shared DMA 0x80000000-0x803d0000 area. After this, the arguments and pointers are copied into a fixed-size private buffer, presumably in an effort to prevent time-of-check-to-time-of-use (TOCTOU) vulnerabilities. This process works similarly to how Linux userland passes arguments with syscalls to the Linux kernel, the kernel using copy_from_user/copy_to_user to safely transfer data across the boundary, and (usually) copying values into the kernel stack for further sanitization and processing.
After this, a per-syscall sanitization function is also called, to validate the sizes of buffers for pointer and reference arguments, and shortly after, the actual syscall is finally called.
At this point, the exploit chain discussed herein is just a gateway to a larger attack surface against Secmon and Pluton. Eventually, this allowed us to analyze Secmon syscalls and spot several issues that we subsequently reported, see TALOS-2021-1309, TALOS-2021-1310, TALOS-2021-1341, TALOS-2021-1342, TALOS-2021-1343, TALOS-2021-1344 and the relative blog post.

0 Comments